Last-modified:2018/08/25 23:32:11.
https://rubygems.org/gems/filerenamer に公開してあります。
多数のファイルを一括リネームするフレームワークと、 それを使った幾つかのリネームコマンドを提供します。
実行前にユーザに変換先のファイル名を提示して、 実行すべきかユーザに問い合わせます。
リネームの結果、ディレクトリが必要になったら自動的に生成します。 また、ディレクトリが空になったら自動的に削除します。
リネーム先のファイル名が元と変化なければ対象から外します。
リネーム先のファイル名が他のファイルと重複する場合には、「Unable files 」 として表示し、リネームは実行されません。
–yes : ユーザに問い合わせることなく実行します。
–no : ユーザに問い合わせることなく実行せずに終了します。
–copy : リネームではなく、コピーを作成します。
–hardlink : リネームではなく、ハードリンクを作成します。
–symlink : リネームではなく、シンボリックリンクを作成します。
–quiet : 画面表示を行いません。–yes も同時に指定したことになります。
ファイル名の先頭文字でディレクトリを作り、その中に入れます。
–kakasi :漢字を kakasi 解析して読みのカナで分類します。
–unite : 英語の大文字を小文字に、濁音・半濁音を清音にしてまとめます。
–length : 先頭1文字ではなく任意の長さで分類します。
–shorten : ディレクトリ名で使った部分の文字列をディレクトリ内では切り詰めます。
–2x2 : たとえば、abcdefgh.txt というファイルを ab/cd/efgh.txt にするように、2文字の2層ディレクトリで分類します。
–length, –shorten, –2x2 なんかは、 私はハッシュ化した名前(see renhash)に対して使うことが多いです。
classify と似ていますが、 こちらは複数のファイル名の中から、ファイル名の重複の長い部分を自動的に判別して 分類ディレクトリを作ります。
classify とはプログラム内の動作が全く異なるため、オプションで纏めずに別コマンドと なっています。
–length : 分類するために最低限一致していなければならない文字数を指定します。 デフォルト値は 1 です。
ファイルのハッシュ値にリネームします。
–command : ハッシュ化に使用するコマンドを指定します。 デフォルトは sha256sum です。
連番にします。 そのリネームで扱う最大番号の桁数に合わせて先頭に 0 をパディングします。
–initial : 先頭ファイルの番号を指定します。デフォルトは 0 です。
–preserve : 元のファイル名を連番のあとに保存します。e.g., old.txt -> 123-old.txt
–random : 番号をシャッフルします。
ファイル名先頭の数字部分をチェックし、対象のファイル群で桁数が揃うように 0 をパディングします。
ファイル名に含まれる括弧に囲まれた部分を拡張子手前に持って行きます。 たとえば、 (ab)c(def)gh.txt -> cgh(ab)(def).txt
文字列を置換します。
–global : ファイル名中に複数回マッチした場合、全て置換します。 デフォルトではオフで、最初にマッチしたものしか置換しません。
–reg-exp : マッチング対象を正規表現パターンで指定します。
例
rensub a A -gディレクトリ内の全てのファイルで a を大文字にします。
rensub / _ */*サブディレクトリのファイルをカレントディレクトリに引っ張り出します。 「mv / ./」と違って、元のディレクトリ名が先頭につきます。
a/b/c という ディレクトリ/ディレクトリ/ファイル があったとする。 これと同じ内容の構造 A/b/c を作りたい。 「cp -r a A」で目的は達成できるが、c が大容量のファイルだったり数が多数だったならディスクスペースを圧迫する。 ディレクトリはそのままでいいが、ファイルだけ(シンボリック)リンクにしたいということがある。 rensub を使って、以下のようにすれば良い。
% rensub --symlink a A **/*(.)大きなディレクトリでファイル数が膨大な時に、 実行できないことがある。 そのような場合、zsh の機能である zargs を使って以下のようにできる。
% zargs -- **/*(^/) -- rensub --symlink a A -yファイルの更新時刻にします。
–preserve : 元のファイル名を時刻情報のあとに残します。
–jpg : JPG に埋めこまれた exif 情報から 日時を取得します。
–tiff : TIFF に埋めこまれた exif 情報から 日時を取得します。 Nikon NEF や Canon CR2 といった RAW データも、これで取得できることがあります。
–separator=char 年/月/日/ のあとの 「/」 のような文字列を指定します。 指定しなければ空文字として扱われます。
FileRenamer::Commander クラスがリネームのフレームワークです。 ユーザは execute メソッドに引数として渡すブロックを作成することで 新しいリネームコマンドを作成できます。
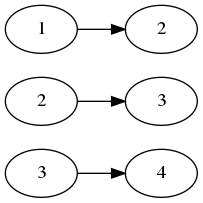
たとえばそれぞれ 1, 2, 3 という名前の連番ファイルがあるとします。 (fig. 1) これを順序を保ったまま 2, 3, 4 に付け替えたいとします。 このとき単純に前から順に処理すると、以下のようにファイルが失われます。
逆順に処理すると意図通りにリネームできます。
では 1, 2, 3 という名前の連番ファイルを、 0, 1, 2 に付け替えたいとしましょう。 今度は逆順だとファイルが失われ、 正順の処理が正解となります。
これらはあるリネーム操作は、他のリネーム操作に依存することがあり、 その依存性を解決する順序を構築する必要がある、ということになります。 勿論、FileRenamer はその機能を提供しています。 先の例では、以下のように処理します。

複数のリネーム処理が相互に依存している場合はどうでしょうか? たとえば 0, 1 というファイル名を 1, 0 のように交換したい場合などです。 この場合は一旦 一時的なファイル名にリネームしてから処理を進める必要があります。
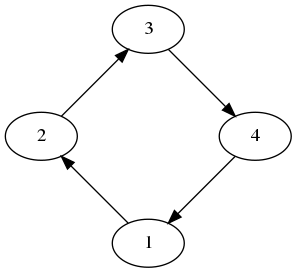
一般的には2体だけでなく、多体での循環型の依存関係で記述できます。 (fig. 3) FileRenamer はこのような循環型の依存関係を検出すると 一時ファイル名を利用して依存関係を解決して処理を行います。